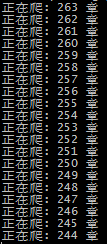
需求
最近在看个漫画,想把所有图片都下载下来存手机里,于是昨天就写了个爬虫。
环境
1
2
3
4
5
6
| // package.json
"cheerio": "^1.0.0-rc.2",
"iconv-lite": "^0.4.18",
"request": "^2.81.0",
"should": "^11.2.1",
"superagent-charset": "^1.2.0"
|
步骤
通过npm init命令创建项目
一路回车就好了。
安装相关的依赖包
npm install
打开网页,通过chrome分析
漫画地址:http://m.kukudm.com/comiclist/1087/index.htm
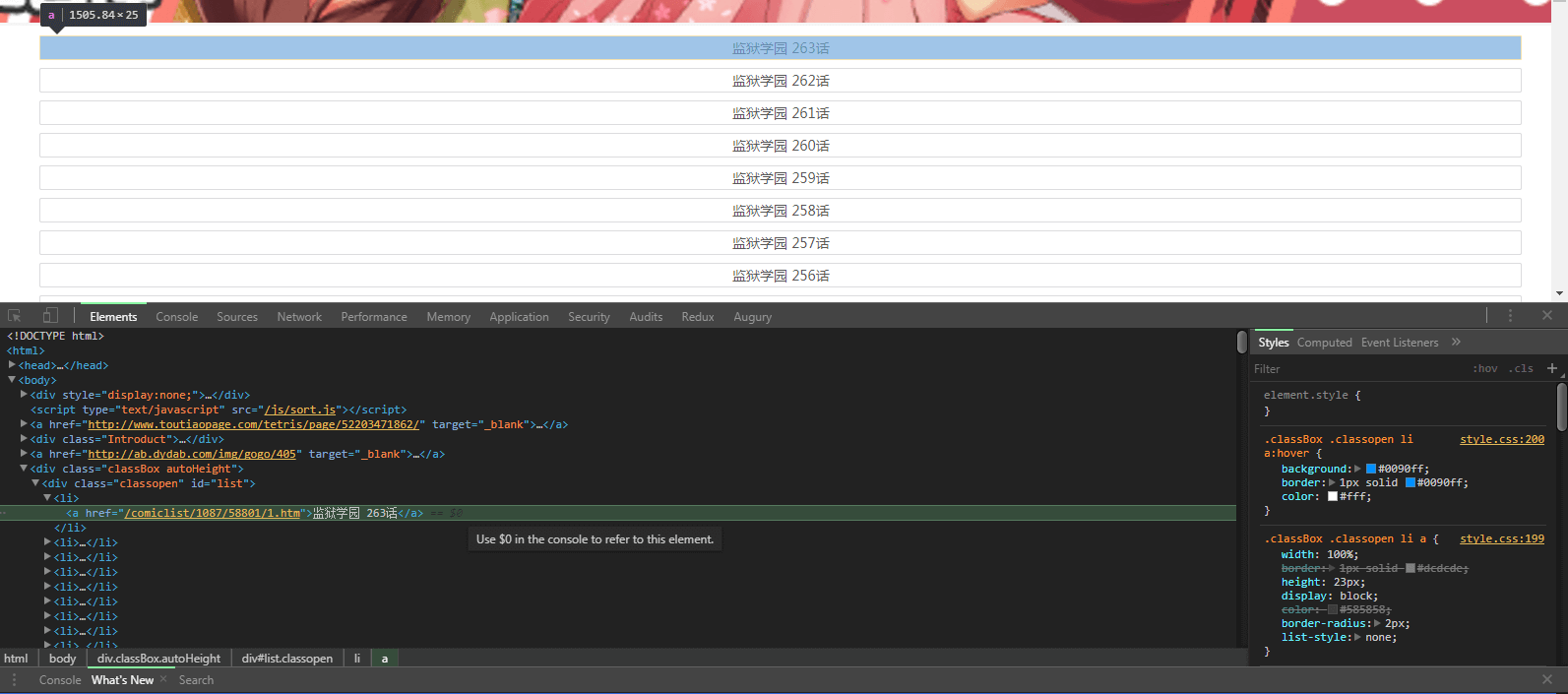
发现所有的章节链接都在 #list > li > a 里面,首先先通过nodejs获取整个html内容,然后提取出来每章漫画的链接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| var http = require('http');
const request = require('superagent')
require('superagent-charset')(request)
request
.get('http://m.kukudm.com/comiclist/1087/index.htm')
.charset('gbk') // 注意 一定得用gbk编码,要不然中文的文字下下来是小方块
.end(function(err, html) {
var $ = cheerio.load(html.text);// 通过cheerio.load载入页面,可以像使用jquery那样操纵下载下来的html
var data = $('#list li a')[0];// 第一个a标签的数据
var pattern = /(\d+)/;// 用正则匹配出来是哪个章节(如 263)
var itemnumber = pattern.exec(data.children[0].data)[0];// 通过a标签的text正则提取章节号
var pageUrl = 'http://m.kukudm.com/' + data.attribs.href;// 通过a标签攒出263章节的地址
})
|
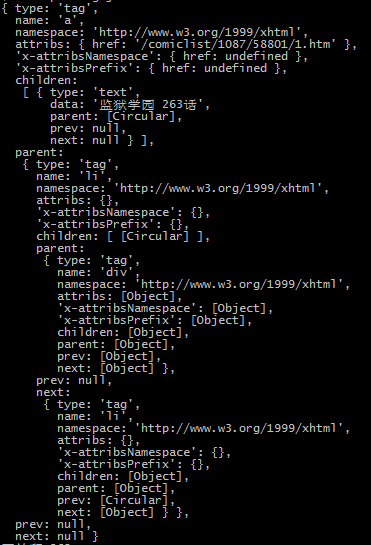
打印一下data对象,如下图:
打开263章节的页面,通过chrome分析
打开 ‘http://m.kukudm.com/‘ + data.attribs.href <===> http://m.kukudm.com/comiclist/1087/58801/1.htm
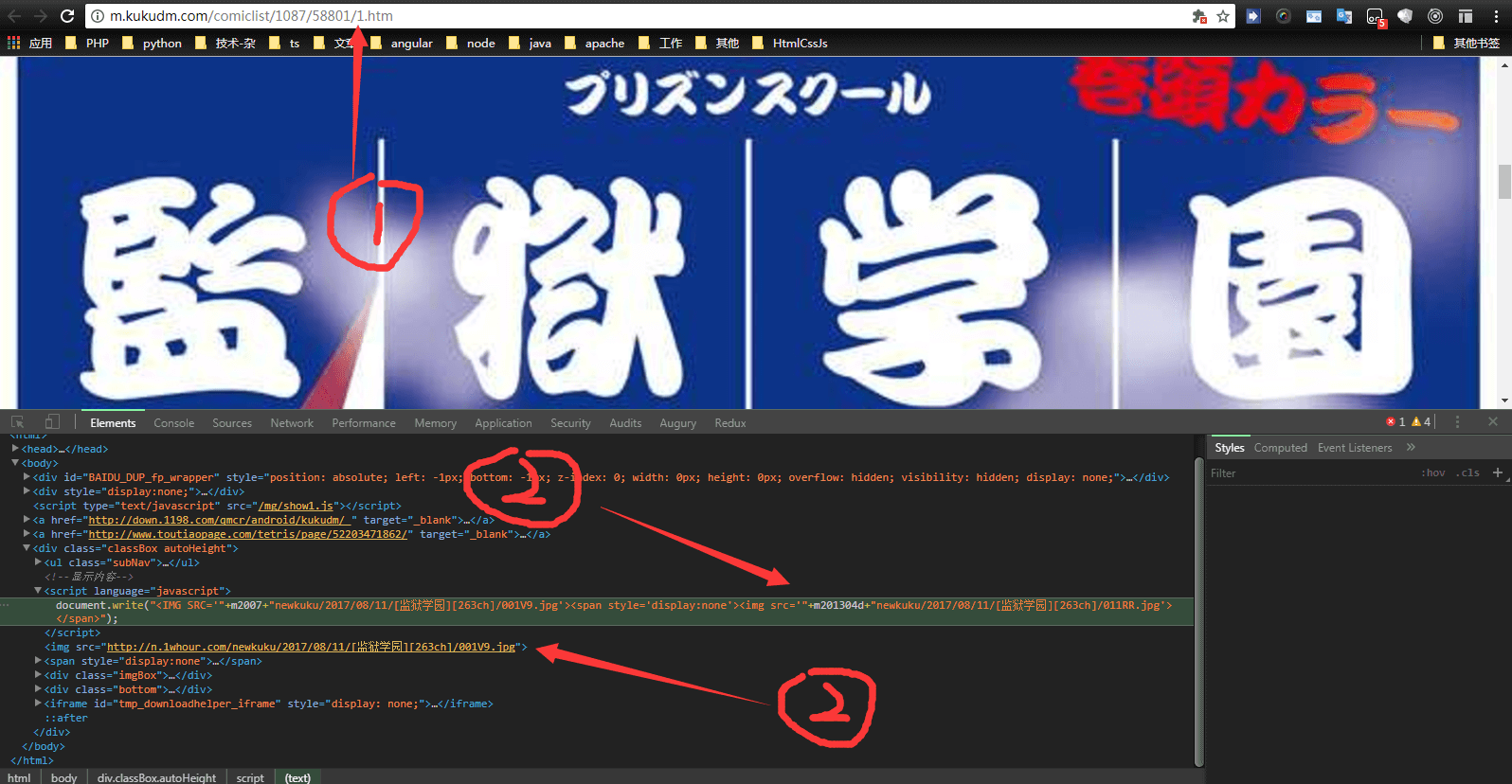
发现两点:
- 第1页最后是1.htm,我就想第二页是不是2.htm,把1改成2一试果然是这样
- 每个漫画的img是通过document.write添加的,不是html页面写好的,看样子还得用正则匹配
用正则匹配img的地址,并下载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| request
.get('http://m.kukudm.com/comiclist/1087/58801/1.htm')
.charset('gbk')
.end(function(err, sres) { // callback
var $$ = cheerio.load(sres.text);
var patternn = /(newkuku[^']*)/; // 用正则匹配真正的img地址
var imageurl = patternn.exec(sres.text)[0];
var encodingimageurl = encodeURI('http://n.1whour.com/' + imageurl);// 因为图片的url地址带中文,得给encoding一下
//下载图片
http.get(encodingimageurl, function(resss) {
var imgData = '';
resss.setEncoding('binary');// 设置成二进制
resss.on('data', function(chunk) {
imgData += chunk;
})
resss.on('end', function() {
fs.writeFile(itemnumber + '/' + i + '.png', imgData, 'binary', function(err) {
if (err) {
console.log("下载图片失败");
}
});
})
})
});
|
说一下正则匹配图片地址
下载下来的sres.text里面,地址长这样:
1
| <img src='"+m201304d+"newkuku/2017/08/11/[监狱学园][263ch]/011RR.jpg'>
|
我在控制台打印了一下 m201304d 这个变量,发现每个页面变量都是一样的,那么只要匹配到最后的 ‘ 就可以了
所以正则 /(newkuku[^’]*)/ 的意思是:从 newkuku 开始匹配,匹配到第一个 ‘ 停止
加上循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| request
.get('http://m.kukudm.com/comiclist/1087/index.htm')
.charset('gbk')
.end(function(err, html) {
var $ = cheerio.load(html.text);
// 我知道一共有263章,于是循环263次
for (let z = 0; z < 263; z++) {
// 用循环的话得来个闭包,因为http是异步的
(function(hello) {
var data = $('#list li a')[hello];
var pattern = /(\d+)/;
var itemnumber = pattern.exec(data.children[0].data)[0];
var pageUrl = 'http://m.kukudm.com/' + data.attribs.href;
console.log('正在爬: ' + itemnumber + ' 章' );
for (let i = 1; i < 30; i++) {
// 这块是组装每页漫画的url的
// pageUrl = http://m.kukudm.com/comiclist/1087/58801/1.htm
var temp1arr = pageUrl.split('/');// 把第一页图片通过/分割
temp1arr.pop(); // 把数组最后的 '1.htm' 弹出去
temp1arr.push(i + '.htm');// push进来一个 'i.htm' i代表页数
var perPageUrl = temp1arr.join('/');// 然后把数组在连成字符串
// 里面是异步请求 还得来个闭包
(function(world) {
request
.get(world)
.charset('gbk')
.end(function(err, sres) { // callback
// 如果一个漫画是18页的话,那么访问第19页的时候页面会返回404,于是我就简单粗暴的把返回的页面字符串通过indexOf的方法查找有没有404这个字符串,有的话就代表这页不存在,下载图片的代码就不执行,没有的话就下载图片
if (sres.text.indexOf('404') == -1) {
var $$ = cheerio.load(sres.text);
var patternn = /(newkuku[^']*)/;
var imageurl = patternn.exec(sres.text)[0];
var encodingimageurl = encodeURI('http://n.1whour.com/' + imageurl);
http.get(encodingimageurl, function(resss) {
var imgData = '';
resss.setEncoding('binary');
resss.on('data', function(chunk) {
imgData += chunk;
})
resss.on('end', function() {
fs.writeFile(itemnumber + '/' + i + '.png', imgData, 'binary', function(err) {
if (err) {
console.log("下载图片失败");
}
});
})
})
}
});
})(perPageUrl)
}
})(z)
}
})
|
最后为了防止访问太快,加个定时器 30秒 下载一章
全部代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| request
.get('http://m.kukudm.com/comiclist/1087/index.htm')
.charset('gbk')
.end(function(err, html) {
var $ = cheerio.load(html.text);
// 我知道一共有263章,于是循环263次
for (let z = 0; z < 263; z++) {
// 定时器 30秒爬一章
setTimeout(function(){
// 用循环的话得来个闭包,因为http是异步的
(function(hello) {
var data = $('#list li a')[hello];
var pattern = /(\d+)/;
var itemnumber = pattern.exec(data.children[0].data)[0];
var pageUrl = 'http://m.kukudm.com/' + data.attribs.href;
console.log('正在爬: ' + itemnumber + ' 章' );
for (let i = 1; i < 30; i++) {
// 这块是组装每页漫画的url的
// pageUrl = http://m.kukudm.com/comiclist/1087/58801/1.htm
var temp1arr = pageUrl.split('/');// 把第一页图片通过/分割
temp1arr.pop(); // 把数组最后的 '1.htm' 弹出去
temp1arr.push(i + '.htm');// push进来一个 'i.htm' i代表页数
var perPageUrl = temp1arr.join('/');// 然后把数组在连成字符串
(function(world) {
request
.get(world)
.charset('gbk')
.end(function(err, sres) { // callback
// 如果一个漫画是18页的话,那么访问第19页的时候页面会返回404,于是我就简单粗暴的把返回的页面通过indexOf的方法查找有没有404这个字符串,有的话就代表这页不存在,下载图片的代码就不执行,没有的话就下载图片
if (sres.text.indexOf('404') == -1) {
var $$ = cheerio.load(sres.text);
var patternn = /(newkuku[^']*)/;
var imageurl = patternn.exec(sres.text)[0];
var encodingimageurl = encodeURI('http://n.1whour.com/' + imageurl);
http.get(encodingimageurl, function(resss) {
var imgData = '';
resss.setEncoding('binary');
resss.on('data', function(chunk) {
imgData += chunk;
})
resss.on('end', function() {
// 我为每一章漫画建了一个文件夹,把第i张图片保存在第itemnumber章的文件夹内
fs.writeFile(itemnumber + '/' + i + '.png', imgData, 'binary', function(err) {
if (err) {
console.log("下载图片失败");
}
});
})
})
}
});
})(perPageUrl)
}
})(z)
},z*30000);
}
})
|
ps: 建立文件夹我用的是以下命令
1
2
3
| for (var i = 1 ; i < 264 ; i++){
fs.mkdir(i);// 好吧 简单粗暴
}
|
总结
low到不行的爬虫,但是能干活,还好这个网站没有什么request头验证啥的,我看漫画去了
欣赏下控制台输出